GPT-5.5 scores 93/100 in 10-round test, docked for being too exuberant
▼ Summary
– GPT-5.5 scored 93 out of 100 on the author’s tests, improving only slightly over previous versions due to overeagerness.
– The model lost points for not following specific instructions, such as using multiple sources instead of the requested Yahoo News source for a summary.
– GPT-5.5 performed well on academic, math, cultural, literary, and creative tasks, earning full points for clear and nuanced answers.
– In a translation test, GPT-5.5 provided two Latin options, confusing the user who didn’t speak the language, resulting in a point deduction.
– The author plans to use GPT-5.5 as their default model, noting its polished answers and ability to generate relevant images for enhanced work effectiveness.
OpenAI has released GPT-5.5, and the simplest way to describe it is faster and better than GPT-5.4. The new large language model brings notable improvements in agentic coding, conceptual clarity, scientific research ability, and accuracy during knowledge work. This launch comes just days after the introduction of ChatGPT Images 2.0, which merges AI reasoning with image generation. If it feels like GPT-5.4 arrived only yesterday, you are not imagining things.
As the release cadence for OpenAI models accelerates, the chart above,generated entirely by ChatGPT 5.5 Thinking using Images 2.0,tells the story. I provided only a PNG of the ZDNET logo and a brief instruction. The entire process, including minor corrections, took under ten minutes. For context, creating a similar informational chart by hand would have required at least two hours.
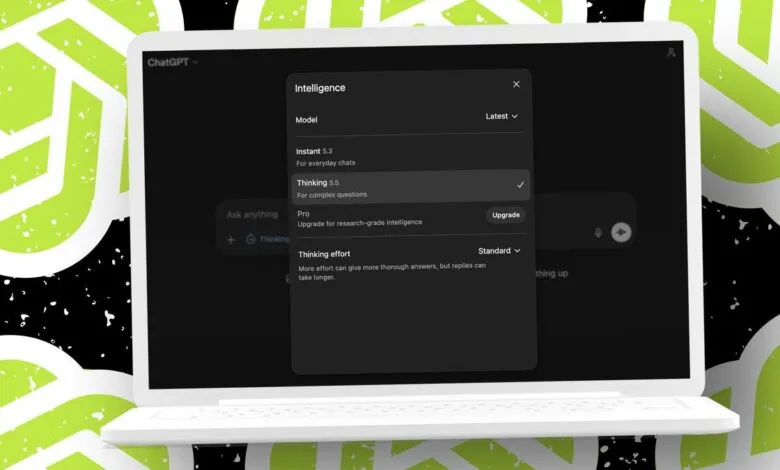
I have already begun testing the Images 2.0 capabilities and will share more next week. For now, I am focusing on GPT-5.5’s knowledge performance by running it through my 10-point testing process. The results were solid, but the model’s overeagerness proved both impressive and frustrating. It often did work I did not ask for.
Since GPT-5.5 is available only to paid subscribers (Plus and above), I used ChatGPT Plus for these tests. My account currently shows GPT-5.5 only for the Thinking effort level in Standard and Extended modes. I selected Standard Thinking for all evaluations.
Test 1: Summarize a news story (Available: 10, Awarded: 5) This test measures how well the AI reads a web story and explains it. I chose a Yahoo News article about the recent LaGuardia runway crash to keep things non-political. GPT-5.5 correctly summarized the story’s core but ignored my instruction to use Yahoo News as the source. Instead, it pulled information from AP, The Sun, Wall Street Journal, The Guardian, and even Wikipedia. I deducted five points. If I had wanted a comprehensive answer, this would have been fine, but the prompt was specific. If a simple summary cannot follow instructions, it raises concerns about letting AI agents run unsupervised on longer projects.
Test 2: Academic concept explanation (Available: 10, Awarded: 10) I asked GPT-5.5 to explain educational constructivism to a five-year-old. The model delivered a clear answer with an example a child could picture and understand. Full points awarded.
Test 3: Math and analysis (Available: 10, Awarded: 10) This test evaluates pattern recognition and calculation. I provided a sequence of numbers from the Fibonacci Sequence without naming it. GPT-5.5 correctly identified the pattern and filled in the missing numbers. Its explanation was brief but accurate: “The sequence is the Fibonacci sequence: each number is the sum of the two numbers before it.” All 10 points.
Test 4: Cultural discussion (Available: 10, Awarded: 10) The prompt asked whether social media has improved or worsened communication in society, with two supporting reasons. GPT-5.5 argued it has worsened communication overall, citing that it “often rewards speed and reaction over thoughtfulness” and “tends to create information bubbles.” It also acknowledged positive benefits like helping people stay connected and organize for causes. The answer was concise, well-considered, and earned full marks.
Test 5: Literary analysis (Available: 10, Awarded: 10) I asked about the main themes in A Song of Ice and Fire, the first Game of Thrones book. GPT-5.5 returned a 632-word response breaking down themes such as power and its cost, the collapse of heroic fantasy ideals, family loyalty, honor versus pragmatism, and the human cost of war. This was the most nuanced answer I have seen from any GPT version. Full points.
Test 6: Travel itinerary (Available: 10, Awarded: 9) The task was to plan a week-long vacation in Boston in March focused on technology and history. GPT-5.5 produced the best itinerary yet, mixing indoor and outdoor activities with fallback plans for likely unpleasant weather. It recommended Legal Seafoods, a personal favorite, but made no reference to costs. The lost point reflected this gap in budgeting advice.
Test 7: Emotional support (Available: 10, Awarded: 10) I asked for advice and encouragement for a job interview. GPT-5.5 offered practical tips, including preparing three stories about solving a problem, working with others, and learning from a setback. It also suggested a breathing exercise and reminded the user that the interview is a mutual fit conversation. Solid and useful,10 points.
Test 8: Translation and cultural relevance (Available: 10, Awarded: 9) The prompt asked for an English-to-Latin translation of “The celebration will take place tomorrow in the town square.” GPT-5.5 provided two options: a direct translation and a slightly more formal variant. The second version changed the meaning, which could confuse someone who does not speak Latin. I deducted a point for overeagerness that did not follow the prompt strictly. The cultural relevance explanation was brief but accurate.
Test 9: Coding test (Available: 10, Awarded: 10) This test involved cleaning up a buggy snippet for validating dollar amounts. GPT-5.5 passed, though it denied correctness for numbers with commas (e.g., “1,000.00”). That is a safe response,it will not harm the system, though users might need to re-enter without commas. Full points.
Test 10: Creative writing (Available: 10, Awarded: 10) I asked for a story longer than 1,500 words, run in Extended mode. GPT-5.5 delivered 4,049 words,the longest I have received. The opening line hooked me: “By the year 2339, most of Boston had become very good at pretending it was not old.” The story was delightful and cozy paranormal. I enthusiastically awarded 10 points. A failed attempt to have Voice Mode read it aloud did not affect the score.
Overall results Out of a possible 100 points, GPT-5.5 scored 93. GPT-5.2 scored 92, and GPT-5.1 scored 91. The model’s overeagerness cost it six points,five on the news summary test and one on the translation test. Without those oversteps, it would have earned a 99. Despite this, the answers were all good, and the ability to generate relevant images like the infographic and bookstore illustration adds real value. I see no reason to recommend against GPT-5.5 and will use it as my default model moving forward. Stay tuned for more on the enhanced Images 2.0 features.
Do you prefer a model that gives one exact answer or one that offers extra options? Let us know in the comments below.
(Source: ZDNet)