Automating AI Research From Start to Finish
▼ Summary
– The research introduces two core automated systems: an AI Scientist to autonomously conduct machine learning research and an Automated Reviewer to evaluate the generated work.
– The AI Scientist operates in two modes: a template-based system that extends a human-provided codebase and a template-free system for more open-ended discovery using a parallelized agentic tree search.
– The template-free system employs a structured, multi-stage experimentation process managed by a progress manager and integrates vision-language models to critique generated figures.
– The Automated Reviewer is an LLM-based agent that emulates peer review, producing structured evaluations and achieving performance comparable to human reviewers on benchmark datasets.
– The research received ethics approval, informed human reviewers that some workshop submissions were AI-generated, and withdrew all AI-generated papers after review.
A new methodology for accelerating scientific discovery relies on two interconnected automated systems: an AI scientist that autonomously conducts research and an automated reviewer that provides rigorous evaluation. This framework explores the potential for artificial intelligence to manage the entire research lifecycle, from initial concept to final manuscript and peer assessment.
The core of this approach is the AI scientist, an agentic system built on large language models (LLMs) that can perform machine learning research independently. It operates in two distinct modes. The first is a template-based system that extends a human-provided code foundation. The second, more ambitious mode is a template-free system designed for open-ended discovery with minimal prior guidance. Both leverage the reasoning and code-generation capabilities of modern LLMs, employing agentic patterns like few-shot prompting and self-reflection to enhance reliability.
The template-based AI scientist begins with a simple code template for a standard benchmark. Its workflow has three phases. First, in idea generation, it enters an iterative loop, using an LLM as a mutation operator to propose new research ideas. Each idea is a structured object with a title, hypothesis, experimental plan, and self-assessed scores for novelty, interest, and feasibility. To ensure originality, the system automatically checks proposals against the scientific literature via the Semantic Scholar API, discarding ideas with high similarity to existing work. It is prompted to act as an ambitious AI PhD student aiming to publish significant work.
Second, during experiment execution, the system selects a promising idea and devises a multi-step plan. It modifies the codebase using the coding assistant Aider, featuring robust error handling. When execution fails, error logs are captured and Aider is invoked for automated debugging, with up to four reattempt cycles. Successful runs log all outcomes in an experimental journal. Third, for manuscript generation, the system synthesizes findings into a full paper. It uses Aider to populate a LaTeX template, writing sections by analyzing the experimental journal and querying Semantic Scholar for related work. The manuscript undergoes several automated editing passes, and LaTeX compilation errors are corrected to produce a final PDF.
To overcome the limitations of a fixed starting point, the template-free AI scientist enables more generalized exploration. It uses a combination of LLMs for different tasks, such as OpenAI’s o3 for reasoning and Anthropic’s Claude Sonnet for code generation. Its generalized idea generation starts by creating high-level research proposals resembling paper abstracts, tightly integrated with a literature review to identify genuine knowledge gaps.
This version introduces an experiment progress manager to coordinate four defined stages: preliminary investigation, hyperparameter tuning, main agenda execution, and ablation studies. Each stage has explicit stopping criteria and conducts its own search. Crucially, experimentation is managed via a parallelized agentic tree search. Instead of a sequential workflow, the system builds a tree of experimental nodes that are executed in parallel, dramatically accelerating exploration.
Each node in the tree undergoes a cycle where Claude Sonnet generates an experiment plan and code. The code is executed, and if successful, results are saved and visualizations are created. These plots are then critiqued by a vision-language model (VLM) like GPT-4o; any issues flagged mark the node as buggy. The system selects nodes to expand, prioritizing buggy nodes for debugging and using a best-first strategy for promising ones. Specialized node types are used for specific needs: hyperparameter nodes for tuning, ablation nodes for component analysis, replication nodes for statistical robustness, and aggregation nodes to summarize results.
The VLM integration is key for quality control, providing feedback on plots during experiments and ensuring figure-caption alignment during manuscript writing. The system also features generalized dataset access, capable of dynamically pulling data from repositories like the HuggingFace Hub by generating the necessary loading code. For manuscript writing, it moves away from incremental editing to direct LaTeX generation using a reasoning model, followed by reflection cycles that incorporate feedback from linters and VLM reviews. The entire generation process can take from several hours to over fifteen, depending on complexity.
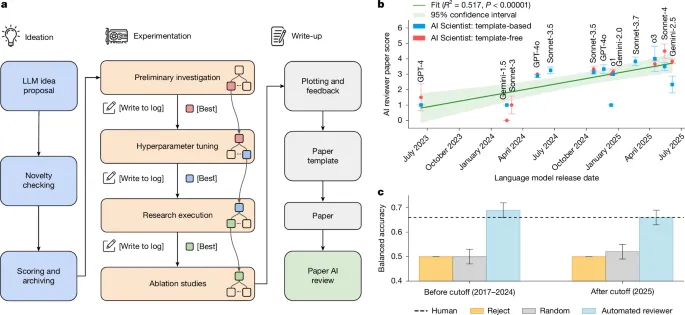
To evaluate the output of these AI scientists, an automated reviewer system was built using o4-mini. Designed to emulate the peer-review process for a top machine learning conference, it adheres to official NeurIPS reviewer guidelines. The agent processes a manuscript PDF to produce a structured review, including scores for soundness, presentation, and contribution, along with strengths, weaknesses, and a preliminary decision.
The review process is multistage. The system is prompted to act as an AI researcher reviewing for a prestigious venue. It outputs a structured JSON response. For robustness, a meta-review ensembles five independent reviews for each paper, with an LLM acting as an area chair to find consensus. Validation against human decisions used data from ICLR’s OpenReview dataset. The automated reviewer achieved comparable balanced accuracy with humans and a higher F1 score compared to inter-human group agreement in the NeurIPS 2021 consistency experiment. This suggests LLM-based agents can provide feedback that aligns with the average human expert, though the paper pools between conferences differed.
(Source: Nature.com)