Grammarly Accused of Using Personal Data Without Consent
▼ Summary
– Grammarly’s “expert review” AI feature generates writing suggestions “inspired by” public figures and journalists, including many who were not asked for permission.
– The feature inaccurately presents some experts’ current job titles and links to questionable or unrelated sources when users seek the cited works.
– A Grammarly executive stated the feature does not claim direct endorsement and includes experts because their published works are publicly available.
– The AI’s suggestions can be misleading, as they are presented in a format that mimics real editorial comments and may offer poor or contradictory advice.
– The article demonstrates that while AI can mimic writing styles, it fails to replicate genuine editorial judgment, even when branded as expert review.
A recent investigation has revealed that Grammarly’s “expert review” feature may be using the names and reputations of prominent individuals without their knowledge or consent. The tool, designed to offer writing suggestions “inspired by” various experts, was found to include notable tech journalists and editors, including several from The Verge, who confirmed they never granted permission for their names to be used. This raises significant questions about data usage, attribution, and the ethical boundaries of AI-powered writing assistants.
The feature, which launched last August, promises to help users refine their text through “industry-relevant perspectives.” It surfaces AI-generated advice attributed to a wide range of public figures, from authors like Stephen King to scientists like Carl Sagan. However, the list extends deeply into the tech media world, including individuals like Wired’s Lauren Goode, Bloomberg’s Mark Gurman, and former Verge editors. Critically, the profiles for these experts often contain outdated or inaccurate job titles, a detail that likely would have been corrected if the company had sought permission from the people involved.
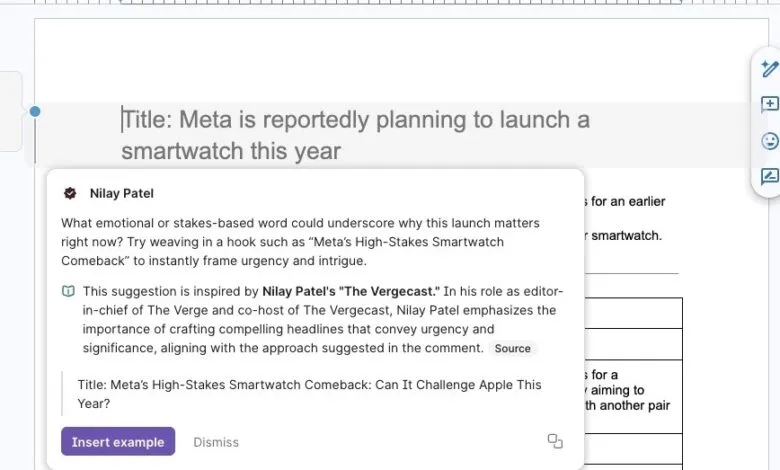
In response to inquiries, a Grammarly representative stated that the tool does not claim direct endorsement from the experts and that individuals are included because their published works are publicly available. The company positions the feature as a way to point users toward influential voices. However, practical testing revealed substantial flaws. The tool frequently crashed, and the source links provided often led to spammy copies of legitimate websites or completely unrelated pages. In some cases, a suggestion attributed to one person’s work appeared to be based on the writing of someone else entirely, undermining the core premise of the feature.
Beyond sourcing issues, the presentation of the AI’s feedback can be misleading. Within platforms like Google Docs, the suggestions are formatted to resemble comments from a real person, creating the illusion of direct input from the named expert. This simulation falters upon closer inspection. For instance, one suggestion “inspired by” a senior editor advised adding contextual information that was already present in the text, a redundancy the actual editor is known to avoid. This highlights a fundamental gap: while an AI can analyze someone’s published writing style, it cannot reliably replicate their editorial judgment or intent.
The situation underscores a growing tension in the AI industry between leveraging publicly available data and respecting individual autonomy. Using a person’s name and professional identity to market an AI feature, without consultation, ventures into ethically murky territory, regardless of whether their work is publicly cited. For users, it presents a reliability problem; if the sources are flawed and the advice is potentially misattributed, the value of the “expert” lens is compromised. As AI tools become more embedded in creative and professional workflows, transparency about how these models are built and whose data informs them will be increasingly vital.
(Source: The Verge)