Bing AI Citations, Hidden Pages & Crawl Limits: SEO Pulse

▼ Summary
– Bing Webmaster Tools launched a public preview of an AI Performance dashboard that tracks how often and why a site’s content is cited in Copilot and AI-generated answers.
– A hidden, outdated HTTP version of a homepage can cause incorrect site names and favicons in Google Search because Googlebot crawls it, even though browsers like Chrome automatically upgrade to HTTPS.
– New data from HTTP Archive shows that the vast majority of webpages are well below Googlebot’s 2 MB HTML fetch limit, making it a non-issue for most sites.
– A common theme across these updates is the closing of “diagnostic gaps” with new tools and data, helping SEO professionals see previously invisible issues like AI citations or server errors.
– Industry reactions highlight that Bing’s new dashboard provides desired AI citation transparency currently lacking in Google’s tools, and that technical issues often require checking server responses directly, not just browser views.
Understanding how search engines interact with your content is becoming more precise, yet the challenge often lies in knowing exactly where to look. Recent developments highlight critical gaps in visibility, from tracking AI citations to uncovering hidden technical issues. These updates provide new diagnostic tools that can significantly refine your SEO strategy.
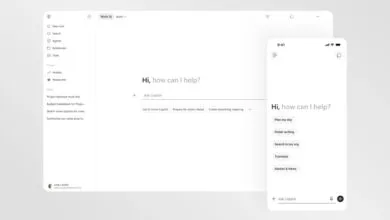
Microsoft has launched a new AI Performance dashboard within Bing Webmaster Tools, now available in public preview. This feature offers publishers direct insight into how often their content is referenced by Copilot and within AI-generated answers. The dashboard tracks several key metrics, including total citations, average cited pages per day, page-level citation activity, and perhaps most importantly, grounding queries. These grounding queries reveal the specific phrases the AI used when retrieving your content to formulate its responses.
This move by Bing provides a level of transparency that has been notably absent. While Google includes some AI Overview activity in its Search Console performance reports, it does not offer a dedicated breakdown or citation-style URL counts. Bing’s dashboard allows you to confirm which pages are being referenced and identify patterns in the queries that trigger citations. However, a significant piece of the puzzle is still missing: click data. The dashboard shows when your content is cited but does not indicate whether those citations actually drive traffic. To connect AI visibility to tangible business outcomes, you must correlate this new data with your own analytics.
Industry professionals have welcomed this development. Wil Reynolds of Seer Interactive highlighted the value of the grounding queries data, while Koray Tuğberk GÜBÜR of Holistic SEO & Digital noted that Bing’s tools often feel more transparent and efficient than Google’s. The shared sentiment across social media reflects a frustration that this much-requested data is coming from Bing rather than Google, with many hoping other platforms will follow suit.
A separate but equally elusive issue involves hidden HTTP pages disrupting how Google displays your site name and favicon. Google’s John Mueller recently detailed a troubleshooting case where a leftover HTTP homepage, invisible during normal browsing, was causing these problems. Because modern browsers like Chrome automatically upgrade HTTP requests to HTTPS, site owners never see the problematic version. However, Googlebot does not follow this upgrade behavior and may crawl the outdated HTTP page instead.
This creates a diagnostic blind spot. If your site name or favicon appears incorrectly in search results despite your HTTPS homepage looking perfect, the HTTP version of your domain is a likely culprit. Mueller suggested using a command-line tool like `curl` to fetch the raw HTTP response or employing the URL Inspection tool in Search Console with a Live Test. This allows you to see exactly what Googlebot retrieves. The core lesson is to check server responses directly, as browser conveniences often mask what crawlers actually see.
Further clarity comes from new data regarding Googlebot’s crawl limits. Updated documentation specifies a 2 MB fetch limit for supported file types like HTML, with a separate 64 MB limit for PDFs. Fresh analysis of HTTP Archive measurements puts this into practical context, revealing that the vast majority of web pages sit comfortably below this 2 MB threshold. The median HTML size for mobile pages is around 33 KB, with 90% of pages under 151 KB.
For most websites, this limit is not a pressing concern. It primarily becomes relevant for pages with excessively bloated markup, large inline scripts, or embedded data that inflates the HTML size. As technical SEO consultant Dave Smart noted, while the limit seems reduced from previously reported figures, 2 MB is still substantial for standard webpage HTML. He updated his diagnostic tool to simulate the cutoff, and John Mueller endorsed this approach for those curious about the impact. The consensus is that for nearly all sites, HTML size can be removed from the list of urgent SEO worries.
This week’s updates collectively address a diagnostic gap in SEO. Practitioners previously lacked tools to measure AI citation impact, could easily miss ghost HTTP pages, and had only theoretical documentation on crawl limits. Now, each area has a concrete diagnostic method: a dedicated dashboard, a specific server check, and validating real-world data. The tools for understanding search engine interactions are becoming more specific, empowering you to look in the right places and optimize with greater confidence.
(Source: Search Engine Journal)